Hive 练习题解答
题目
在 Github 上面找了一些题目来练习
https://github.com/zzyb/Hive_interview-question
解答
answer
1 | -- 第一道面试题 |
在 Github 上面找了一些题目来练习
https://github.com/zzyb/Hive_interview-question
1 | -- 第一道面试题 |
spark-shell
spark-sql
scala code
CSV
JSON
Parquet
ORC
JDBC/ODBC connections
Plain-text files
1 | // 格式 |
| 读模式 | 描述 |
|---|---|
permissive |
当遇到损坏的记录时,将其所有字段设置为 null,并将所有损坏的记录放在名为 _corruption t_record 的字符串列中 |
dropMalformed |
删除格式不正确的行 |
failFast |
遇到格式不正确的数据时立即失败 |
1 | // 格式 |
| Scala/Java | 描述 |
|---|---|
SaveMode.ErrorIfExists |
如果给定的路径已经存在文件,则抛出异常,这是写数据默认的模式 |
SaveMode.Append |
数据以追加的方式写入 |
SaveMode.Overwrite |
数据以覆盖的方式写入 |
SaveMode.Ignore |
如果给定的路径已经存在文件,则不做任何操作 |
1 | // 简写法 |
1 | help 'create' |
HBase是没有schema的,就是在创建表的时候不需要指定表中有哪些列,只需要指定有多少个列蔟
1 | # 创建订单表,表名为ORDER_INFO,该表有一个列蔟为C1 |
1 | # 查看表 |
1 | # 删除表 |
1 | # 添加一条数据 |
删除数据的时候,其实 HBase 不是真的直接把数据删除掉,而是给某个列设置一个标志,然后查询数据的时候,有这个标志的数据,就不显示出来
什么时候真正的删除数据呢?
执行 delete 的时候
- 如果表中的某个列有对一个的几次修改,它会删除最近的一次修改
- 默认是保存 1 个保存的时间戳
- 有一个 version 属性
1 | # 统计表行数 |
count 执行效率非常低,适用于百万级以下的小表 RowCount 统计
利用 hbase.RowCounter 包执行 MR 任务
1 | # 在 shell 中执行 |
1 | # 全表扫描:scan "表名"(慎用,效率很低) |
其实在hbase shell中,执行的ruby脚本,背后还是调用hbase提供的Java API
1 | # 查看内置过滤器 |
1 | # 使用 RowFilter 查询指定订单ID的数据 |
通过上图,可以分析得到,RowFilter过滤器接受两个参数,
op——比较运算符
rowComparator——比较器
所以构建该Filter的时候,只需要传入两个参数即可
1 | # 查询状态为「已付款」的订单 |
HBase shell中比较默认都是字符串比较,所以如果是比较数值类型的,会出现不准确的情况
例如:在字符串比较中4000是比100000大的
| RowFilter | 实现行键字符串的比较和过滤 |
|---|---|
| PrefixFilter | rowkey前缀过滤器 |
| KeyOnlyFilter | 只对单元格的键进行过滤和显示,不显示值 |
| FirstKeyOnlyFilter | 只扫描显示相同键的第一个单元格,其键值对会显示出来 |
| InclusiveStopFilter | 替代 ENDROW 返回终止条件行 |
| FamilyFilter | 列簇过滤器 |
|---|---|
| QualifierFilter | 列标识过滤器,只显示对应列名的数据 |
| ColumnPrefixFilter | 对列名称的前缀进行过滤 |
| MultipleColumnPrefixFilter | 可以指定多个前缀对列名称过滤 |
| ColumnRangeFilter | 过滤列名称的范围 |
| ValueFilter | 值过滤器,找到符合值条件的键值对 |
|---|---|
| SingleColumnValueFilter | 在指定的列蔟和列中进行比较的值过滤器 |
| SingleColumnValueExcludeFilter | 排除匹配成功的值 |
| ColumnPaginationFilter | 对一行的所有列分页,只返回 [offset,offset+limit] 范围内的列 |
|---|---|
| PageFilter | 对显示结果按行进行分页显示 |
| TimestampsFilter | 时间戳过滤,支持等值,可以设置多个时间戳 |
| ColumnCountGetFilter | 限制每个逻辑行返回键值对的个数,在 get 方法中使用 |
| DependentColumnFilter | 允许用户指定一个参考列或引用列来过滤其他列的过滤器 |
| 比较器 | 描述 |
|---|---|
| BinaryComparator | 匹配完整字节数组 |
| BinaryPrefixComparator | 匹配字节数组前缀 |
| BitComparator | 匹配比特位 |
| NullComparator | 匹配空值 |
| RegexStringComparator | 匹配正则表达式 |
| SubstringComparator | 匹配子字符串 |
| 比较器 | 表达式语言缩写 |
|---|---|
| BinaryComparator | binary:值 |
| BinaryPrefixComparator | binaryprefix:值 |
| BitComparator | bit:值 |
| NullComparator | null |
| RegexStringComparator | regexstring:正则表达式 |
| SubstringComparator | substring:值 |
incr可以实现对某个单元格的值进行原子性计数。语法如下:
incr ‘表名’,’rowkey’,’列蔟:列名’,累加值(默认累加1)
如果某一列要实现计数功能,必须要使用incr来创建对应的列
使用put创建的列是不能实现累加的
1 | # 通过 scan/get 无法直接查看cnt |
1 | # 对0000000020新闻01:00 - 02:00访问计数+1 |
1 | # 显示服务器状态 |
1 | hbase shell 'script file path' |
web默认端口16010
https://blog.csdn.net/u013411339/article/details/120795941
https://blog.csdn.net/qq_44065303/article/details/105820435
服务端要开启 hiveserver2
1 | -- 1.正常建表 |
1 | -- 查看内置函数 |
1 | -- 公用表表达式 |
1 | 语法: unix_timestamp() |
1 | 语法: datediff(string enddate, string startdate) |
1 | -- 共4种用法 |
partition by
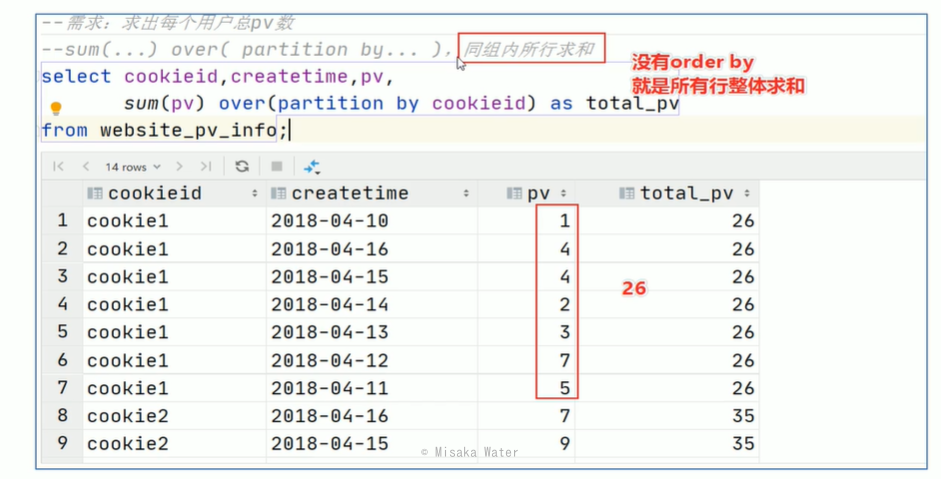
order by

窗口表达式提供了一种控制行范围的能力如往前,往后n行
可以写多个列
1 | -- 默认从第一行到当前行 |
1 | -- row_number家族,在每个分组中,为每行分配一个从1开始的唯一序号 |
1 | -- 窗口排序函数 ntile |
随机,但是速度慢
1 | select * from website_pv_info order by rand() limit 2; |
速度快,但是不随机
1 | -- 按行数抽样 |
速度快+随机
tablesample(BUCKET x OUT OF y [ON colname])
1 | -- 根据整行数据进行抽样 |
1 | -- CAST可以转换的类型 |
1 | -- CONCAT 函数用于将多个字符串连接成一个字符串。 |
1 | -- 简单 case |
1 | -- explode |
1 | -- 多行转多列 |
1 | /* |
1 | select * from ( |
1 | LAG(列名,前几行,'默认值') |

1 | -- 原数据 |
1 | -- 编写Hive的HQL语句求出每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数 |
之前报名了学校的一些大数据比赛,做的笔记整理一下发出来,供以后查看
第一次用 ide 和 scala,不足之处还请批评指正
在 idea 中建立一个 maven 工程,注意路径不能包括中文
添加 pom.xml,示例在 Source\Task3\example\pom.xml 中
1 |
|
在 Idea 左侧 Project 窗口中选中 src\main 右键添加文件夹 scala
选中 scala 右键 make directory as -> Sources Root
scala 变成蓝色后右键 new -> scala class ->选择 object,输入名称
我们先写一个最简单的 CsvShow 程序让他能在本地运行并且 debug
1 | package org.example.spark.scala |
解压 Hadoop,在没有安装 hadoop 的情况下是不能进行 spark 程序的本地 debug
我们先下载如下两个文件 hadoop-2.6.0.tar.gz 和 hadooponwindows-master.zip
先将 hadoop 解压出来
再解压 hadooponwindows 到 hadoop 的根目录下,提示覆盖选择全覆盖
添加如下环境变量
打开 cmd,输入 hadoop version,显示版本说明 hadoop 环境变量配置正确
修改 etc\hadoop\hadoop-env.cmd 中的 JAVA_HOME,如 JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_241,路径中不能有空格
在根目录下添加 datanode、namenode 和 tmp 文件夹
修改 etc\hadoop\hdfs-site.xml,添加如下 xml, 注意/D:/hadoop-2.6.0/namenode 和/D:/hadoop-2.6.0/datanode 这两个值需要时之前创建文件夹的路径
1 | <configuration> |
1 | <configuration> |
1 | <configuration> |
1 | <configuration> |
