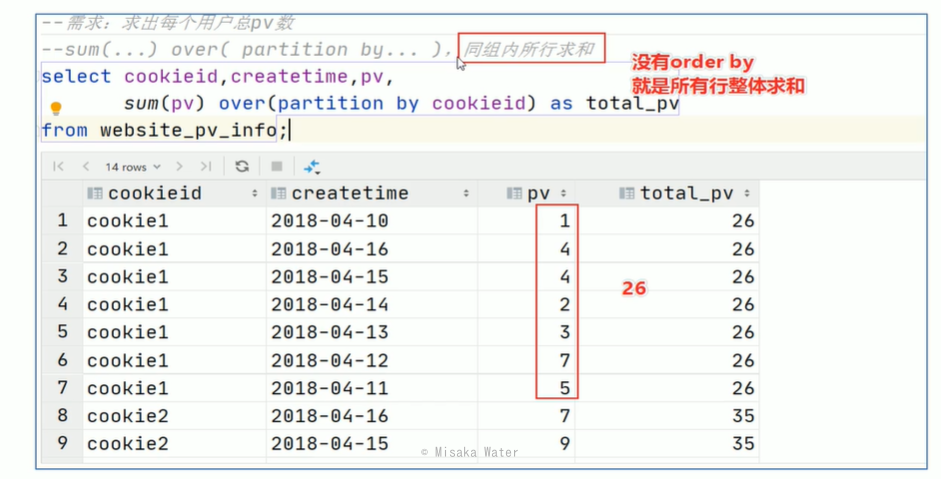
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
|
select distinct user_id
from (
select user_id,
lag(login_date,1) over (partition by user_id order by login_date) prev,
login_date now,
lead(login_date,1) over (partition by user_id order by login_date) next
from login_log) t where datediff(now,prev) = 1 and datediff(next,now)=1;
select name,mon,monMoney,accMonMoney
from(
select name,mon,sum(monmoney) over (partition by name,mon) monMoney,
sum(monmoney) over (partition by name order by mon) accMonMoney,
row_number() over (partition by name,mon order by mon) top
from fangwen2)t where top=1;
select usr,mon,num,col1 monPv,col2 maxMonPv,col3 accMonPv from(
select usr,mon,num,sum(num) over (partition by usr,mon) col1,
max(num) over (partition by usr,mon) col2,
sum(num) over (partition by usr order by mon) col3,
row_number() over (partition by usr,mon order by mon) col4 from fangwen) t where col4=1;
select usr,mon,maxPv,totalPv from(
select usr,mon,num,
max(num) over (partition by usr,mon) maxPV,
sum(num) over (partition by usr order by mon) totalPv,
row_number() over (partition by usr,mon order by mon) top
from fangwen) t where top=1;
select day,mac,color,num,
sum(num) over (partition by day,mac)
from mac;
select t.c_year,max(t.c_temp) from (
select year(from_unixtime(unix_timestamp(substr(line,0,8),'yyyyMMdd'))) c_year,substr(line,9,2) c_temp from wendu
) t group by t.c_year;
select dt,year(dt),temp
from(
select concat_ws('-',substring(line,0,4),substring(line,5,2),substring(line,7,2)) dt,
substring(line,9,2) temp,
row_number() over (partition by substring(line,0,4) order by substring(line,9,2) DESC) top
from wendu) subT where top=1;
select dt,temp
from(
select concat_ws('-',substring(line,0,4),substring(line,5,2),substring(line,7,2)) dt,
substring(line,9,2) temp,
row_number() over (partition by substring(line,0,4) order by substring(line,9,2) DESC) top
from wendu) subT where top=1;
select t.c_year,t.c_date,t.c_max from
(select
year(from_unixtime(unix_timestamp(substr(line,0,8),'yyyyMMdd'))) c_year,
from_unixtime(unix_timestamp(substr(line,0,8),'yyyyMMdd')) c_date,
row_number() over(partition by year(from_unixtime(unix_timestamp(substr(line,0,8),'yyyyMMdd'))) order by substr(line,9,2) DESC) as c_rank,
substr(line,9,2) c_max
from wendu) t where t.c_rank = 1;
select * from(
select sid,
max(case course when 'yuwen' then course end) yuwen,
max(case course when 'yuwen' then score end) yuwenScore,
max(case course when 'shuxue' then course end) shuxue,
max(case course when 'shuxue' then score end) shuxueScore,
max(case course when 'yingyu' then course end) yingyu,
max(case course when 'yingyu' then score end) yingyuScore
from chengji group by sid) t where t.shuxueScore > t.yuwenScore;
select sid,t1score yuwen,t2score shuxue from(
select * from (
select sid,course,score t1score
from chengji
where course = 'yuwen'
) t1
join (
select sid,course,score t2score from chengji where course = 'shuxue'
) t2 on t1.sid = t2.sid) t3 where t3.t2score > t3.t1score;
select id,
max(case course when 'a' then 1 ELSE 0 end) a,
max(case course when 'b' then 1 ELSE 0 end) b,
max(case course when 'b' then 1 ELSE 0 end) b,
max(case course when 'c' then 1 ELSE 0 end) c,
max(case course when 'd' then 1 ELSE 0 end) d,
max(case course when 'e' then 1 ELSE 0 end) e,
max(case course when 'f' then 1 ELSE 0 end) f
from id_course group by id;
select id,name,maxAge,favor
from (
select id, name, max(age) over (partition by favor) maxAge, favor,
row_number() over (partition by favor order by age DESC) top
from aihao lateral VIEW explode(split(favors, '-')) t1 as favor
)t2 where top=1;
select id,name,maxAge,favor
from (
select id, name, max(age) over (partition by favor) maxAge, favor,
row_number() over (partition by favor order by age DESC) top
from aihao lateral VIEW explode(split(favors, '-')) t1 as favor
)t2 where top<=2;
insert into goods values ('2018-04-07','d','5000','3000');
select d_month,profit,avgCost from (
select concat(year(dt),'-',month(dt)) d_month,name,income,cost,
(sum(income) over(partition by concat(year(dt),'-',month(dt))) -
sum(cost) over(partition by concat(year(dt),'-',month(dt)))) profit,
avg(cost) over(partition by concat(year(dt),'-',month(dt))) avgCost,
row_number() over (partition by concat(year(dt),'-',month(dt)) order by name) top
from goods where year(dt) = '2018') t_month where t_month.top=1;
select
dt,cost,
(cost - LAG(cost,1,cost) over(partition by concat(year(dt),'-',month(dt)) order by dt))
from goods where concat(year(dt),'-',month(dt)) = '2018-3';
select concat(year(dt),'-',month(dt)),name,sum(income) sumIncome
from goods where concat(year(dt),'-',month(dt)) = '2018-4'
group by name,concat(year(dt),'-',month(dt)) having sumIncome>22000;
select g.dt,maxT.name,maxT.maxIncome,g.income,g.cost from(
select name,totalIncome,max(totalIncome) over() maxIncome from(
select
dt,name,income,cost,
sum(income) over (partition by name) totalIncome
from goods where concat(year(dt),'-',month(dt)) = '2018-4') t limit 1
) maxT join goods g on maxT.name=g.name where concat(year(dt),'-',month(dt)) = '2018-4';
|