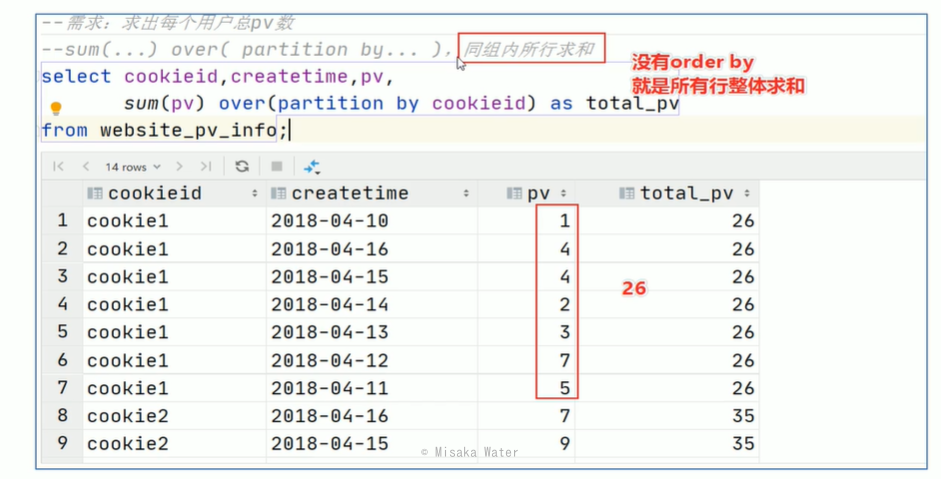
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
usr,mon,num
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,11
sum(num) over (partition by usr order by mon) accPV
with t as (
select usr,mon,num,
row_number() over (partition by usr,mon order by num DESC) top,
sum(num) over (partition by usr order by mon) accPV
from fangwen
)select usr,mon,num,accPV from t where top=1;
|